
一个反直觉的发现
如果你有机会翻开一个生产级 AI 编码 Agent 的源码,你最先期待看到什么?模型调用的逻辑?工具执行的编排?权限控制的判断?
你可能不会期待看到这个:在 Claude Code 中,控制模型行为的主要手段不是代码逻辑,而是提示词。
这不是比喻。当我们说"控制面"的时候,在传统软件中,它意味着 if-else 分支、策略模式、配置中心——总之,是代码。但在 Claude Code 的世界里,系统提示词的每一段落都在引导模型该做什么、不该做什么、优先做什么、什么条件下放弃。工具描述不是静态字符串,而是根据权限模式动态生成的函数。89 个 Feature Flag 中的大部分不是控制代码路径,而是控制注入到提示词中的内容。
这就像你发现一辆汽车的转向系统不是机械连杆,而是驾驶员的语音指令——而且它真的管用。
《驾驭工程》这本书,把从 Claude Code v2.1.88 源码中逆向分析出的这些发现,提炼成了一个更深的命题:当 AI 成为系统的执行者,“控制"这件事本身需要被重新定义。 这不是一个 Prompt Engineering 的问题,而是一个全新的工程学科的问题。
驾驭工程 ≠ Prompt Engineering
先说清楚一件事:驾驭工程不是 Prompt Engineering 的升级版。
Prompt Engineering 解决的核心问题是:如何让模型在一次交互中给出更好的回答。它的基本单位是"一条提示词”,它的优化目标是"这一次的输出质量"。
驾驭工程解决的核心问题是:如何设计一个系统,让 AI 在长时间、多轮次、有状态的执行过程中,始终表现出可预测、可控、可靠的行为。它的基本单位是"一个系统",它的优化目标是"整个运行周期的行为一致性"。
这个区别是本质性的。打个比方:Prompt Engineering 是教你如何跟一个聪明的临时工说清楚一次任务的要求;驾驭工程是设计一套组织架构、流程规范和文化系统,让一千个聪明的临时工在没有任何直接监督的情况下,持续做出一致的决策。
从 Claude Code 的源码中,我们可以清楚地看到这种系统性思维的具体形态:
- Agent Loop 不是一个简单的 while 循环,而是一个包含了权限拦截、并发编排、流式中断和压缩触发的状态机
- 系统提示词 不是一个静态文本块,而是一个由多个段落按条件拼接的动态文档——模型身份、工具描述、上下文压缩结果、用户覆盖层,每一层都在运行时注入
- 工具注册 有四种策略:无条件注册、构建时 Flag 守卫、运行时环境变量守卫、运行时函数守卫——同一套工具在不同模式下呈现给模型的面貌完全不同
- 工具描述是函数而非字符串 ——同一个
Write工具在 allowlist 模式下和默认模式下的描述不一样,因为模型需要知道的信息取决于它当前被授予的权限
这些不是"高级提示词技巧",这是系统架构。
六条原则:一套约束体系,而非六条独立建议
《驾驭工程》提炼了六条核心原则。如果逐条罗列,它们看起来像是"好习惯清单"。但一旦你把它们放回 Claude Code 的工程语境中,就会发现它们构成了一套彼此制约的约束体系——任何一条离开其他五条,都会走向极端。
提示词即控制面 → 缓存感知设计是刚需
第一条原则说"用提示词引导行为",第三条说"缓存感知设计是刚需"。这两条是一对双子。
当你把行为控制从代码层移到提示词层,你获得了极大的灵活性——不用改代码就能改变模型行为。但代价是:每一次提示词变更都意味着缓存失效。在 Claude 的 Prompt Cache 机制下,缓存失效不是"变慢一点"那么简单,而是以 cache_creation token 计量的真金白银。
书中的一个具体数据点:agent 列表曾占缓存前缀的 10.2% 的 cache_creation token。这意味着仅仅是在缓存前缀中多传了一个 agent 列表,每次会话都要为这 10.2% 付出额外成本。后来这个列表被移出前缀,这是一个纯粹的缓存优化决策——跟功能无关,跟成本有关。
所以"提示词即控制面"和"缓存感知设计"不是两条独立的原则,而是一个硬币的两面:你用提示词获得灵活性,就必须用缓存设计来支付灵活性带来的成本。
失败关闭,显式开放 → 锁存以求稳定
第四条原则"失败关闭,显式开放"说的是默认值的选择:当你不确定,选最安全的选项。第六条原则"锁存以求稳定"说的是:一旦进入某个状态,就不再摇摆。
在 Claude Code 的 Beta Header 机制中,这两条原则的联合作用体现得淋漓尽致:一旦某个会话发送过某个 beta header,就永远继续发送,即使对应的功能已经被关闭。这不是偷懒,而是有意为之——因为如果你在会话中途停止发送某个 header,模型的缓存前缀就会改变,之前所有的缓存都会失效,而此时模型可能正在基于之前的上下文执行一个复杂的重构任务。
“锁存"的代价是你会带着一些已经不需要的 header 继续运行,但收益是缓存稳定性和行为一致性。这是一个典型的工程权衡——选择确定性而非最优性。
先观察再修复 → A/B 测试一切
第五条和第四条原则看似矛盾:一个说"先观察”,一个说"先测试"。但实际上它们处理的是不同阶段的问题。
“先观察再修复"针对的是你还不理解的问题——在 Claude Code 的实践中,压缩熔断器的设计就是典型案例。最初系统发现有 1279 个会话经历了 50 次以上的连续压缩失败,每天浪费 250K 次 API 调用。在建立可观测性之前,你甚至不知道这个问题存在,更不可能修复它。
“A/B 测试一切"针对的是你想要改变的行为——通过 GrowthBook 平台上的 tengu_* 系列运行时 Flag,Claude Code 可以在不修改代码的情况下改变模型的提示词注入策略,然后在内部用户群体中验证效果。
两条原则合在一起构成了一个完整的决策链路:先建立可观测性理解问题,再用 A/B 测试验证解决方案。缺了前者,你的测试是盲目的;缺了后者,你的修复是未经验证的。
缺陷即权衡:5 个不足背后的工程选择
《驾驭工程》没有止步于赞美,它在最后一章坦诚地列出了 Claude Code 的五个不足。但如果你仔细看,这五个"不足"与其说是 bug,不如说是特定工程约束下的理性选择。理解这些权衡,比简单地批评不足有价值得多。
缓存脆弱性:分散注入点导致的代价
问题:提示词的各个段落从不同位置注入,任何一个注入点的变更都可能导致缓存中断。
但你想想:如果为了缓存稳定性,把所有提示词合并成一个巨大的静态块,你就失去了按条件注入的灵活性——工具描述需要根据权限模式变化、用户覆盖层需要根据 CLAUDE.md 内容变化、压缩结果需要根据上下文状态变化。缓存脆弱性是动态性的直接代价。你不可能同时拥有"提示词随状态变化"和"缓存永远命中”。
压缩信息丢失:7:1+ 压缩比的必然
当上下文超过 Token 预算时,Claude Code 会触发自动压缩,将对话历史压缩成摘要。7:1 的压缩比意味着每 7 个 token 的原始信息被压缩成 1 个 token 的摘要——信息丢失是不可逆的。
但替代方案是什么?不做压缩?那模型上下文窗口会溢出,导致后续所有推理质量崩塌。压缩比选小一点?那单次会话能承载的上下文就短了,复杂的长期重构任务就无法完成。压缩是两个糟糕选项中较不糟糕的那个,而压缩熔断器(连续 3 次失败后停止)是防止更坏情况的安全阀。
Grep 不是 AST:40+ 工具中无 AST 查询工具
Claude Code 的文件搜索完全依赖 grep,没有语法树感知能力。这意味着它无法区分字符串中的"函数调用"和真正的函数调用,无法理解代码的结构语义。
这确实是一个限制。但想想 AST 查询工具的设计复杂度:你需要为每种语言维护解析器、处理语法错误、在部分文件不完整时优雅降级——这不是一个工具的工程量,而是一个子系统的工程量。在一个已经拥有 40+ 工具的系统中,AST 工具的 ROI 可能不足以支撑其复杂度。这不是不知道 AST 更好的问题,而是在有限的工程资源下优先级排序的问题。
截断告知不足:预览不保证被读取
当工具返回的内容超过限制时,系统会截断并告知模型"内容已被截断”。但模型是否真的会基于这个告知做出正确决策——比如去读取完整文件而不是凭截断内容猜测?书中指出,这一点并不总是可靠的。
这是一个更深层的信任问题:你在提示词中告诉模型"内容被截断了,请读取完整文件",但你无法保证模型真的会这么做。这不是代码逻辑可以强制执行的——因为模型是概率性的执行者,不是确定性的函数。“失败关闭"原则在这里碰到了它的边界:你可以设置默认行为,但你无法保证模型 100% 遵守。
89 个 Flag 的组合爆炸
89 个 Feature Flag 的理论组合数量是 2^89——这是一个天文数字。即使只有一小部分 Flag 之间存在交互效应,测试覆盖也几乎不可能完备。
但回看双层 Flag 的设计:构建时 feature() 决定代码是否进入 bundle,运行时 tengu_* 决定运行时行为。这个分层本身就是在控制复杂性——构建时 Flag 消除了不可能的组合(代码不存在就不会执行),运行时 Flag 通过 GrowthBook 平台集中管理,而不是散落在代码各处。
更重要的是,这 89 个 Flag 不是随机生长的。书中揭示的 KAIROS 家族——6 个 Flag 指向同一个"助手模式"产品——说明 Flag 是产品路线图的投影。Flag 的数量是产品复杂度的函数,而不是工程疏忽的结果。

从 Claude Code 看驾驭工程的未来
把视角从 Claude Code 拉开,我认为驾驭工程这个概念指向了三个行业级别的方向。
第一,AI Agent 系统需要自己的"设计模式”
1994 年 GoF 出版《设计模式》时,面向对象编程已经存在了多年,但开发者还在用试错的方式组织代码。设计模式的贡献不是发明了什么新技术,而是给已有的实践命名,让开发者有共同的语言来讨论架构选择。
驾驭工程正处于类似的阶段。Claude Code 中使用的模式——动态提示词拼接、缓存前缀设计、压缩熔断器、Beta Header 锁存、双层 Feature Flag——这些实践已经存在了,但它们还没有被系统化地命名和分类。当更多的 AI Agent 系统被构建出来,这些模式会以不同形式反复出现,而驾驭工程有可能成为这个领域的"设计模式"语言。
第二,控制面的分离是必然趋势
在传统软件中,业务逻辑和控制逻辑的分离是成熟的做法——依赖注入、AOP、配置中心都是这个方向的产物。在 AI Agent 系统中,“提示词即控制面"正在推动一个更根本的分离:模型行为控制与代码逻辑的分离。
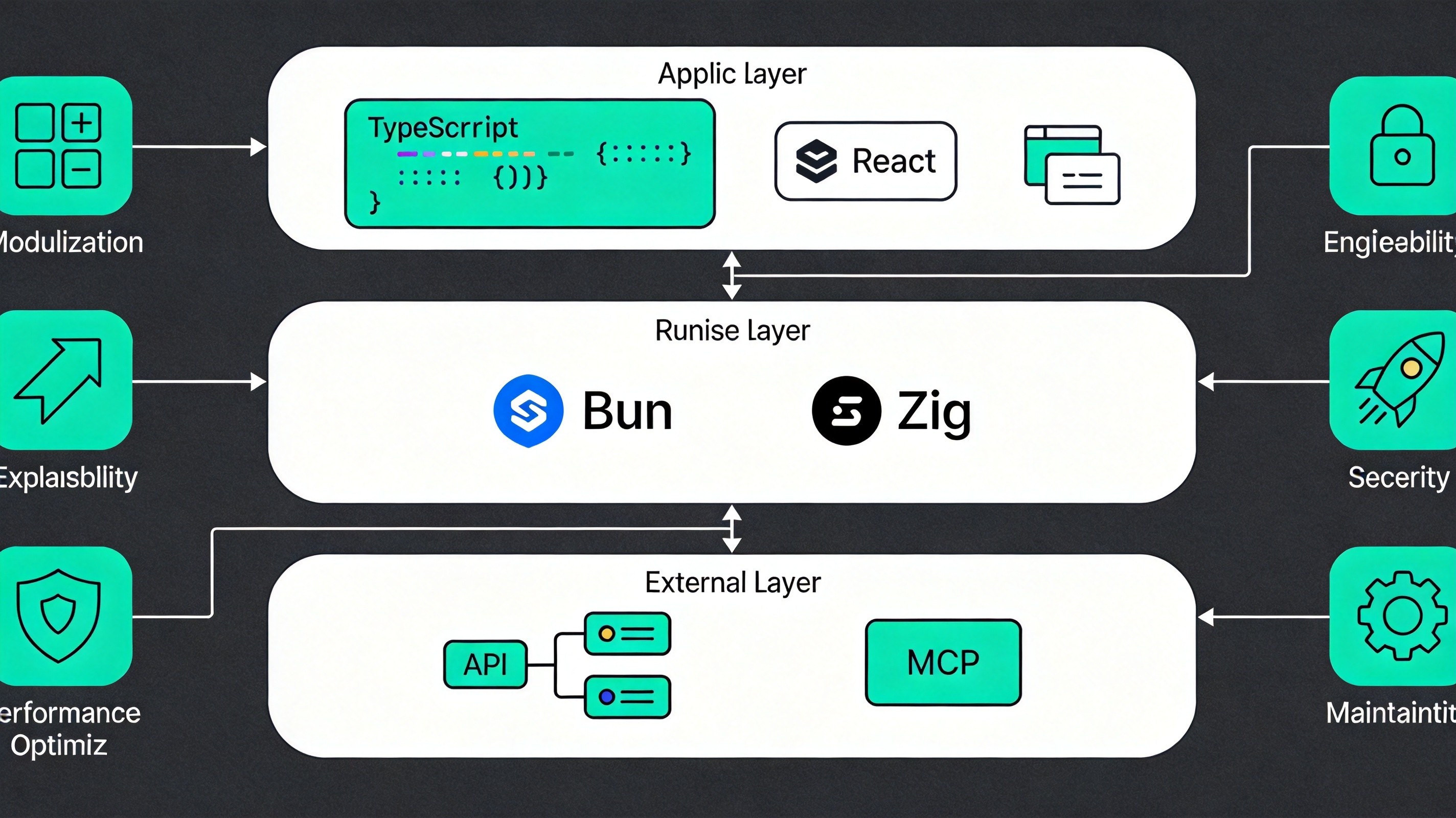
Claude Code 的三层架构(应用层 TS → 运行时层 Bun/Zig/JSC → 外部依赖层 npm/API/MCP/GrowthBook)中,最上层和最底层之间的通讯不是通过函数调用,而是通过提示词。模型不调用函数——它"表达意图”,工具系统将意图转化为执行。这种间接性是驾驭工程的根基,也是它与传统软件工程最大的分歧点。
这种分离带来的好处是显而易见的:你可以在不改代码的情况下改变模型行为(通过修改提示词和 Flag),你可以在不重新部署的情况下改变策略(通过 GrowthBook)。但代价同样明显:行为不再是代码可审计的。你无法通过阅读代码来完整理解系统在做什么,因为一部分行为存在于提示词中,一部分存在于模型的权重中,只有两者交互时才产生实际行为。
第三,可观测性将成为驾驭工程的第一公民
Claude Code 源码中最让我印象深刻的细节之一,不是某个精妙的设计,而是那 1279 个会话经历了 50+ 次连续压缩失败的发现。这个数字不是假设,不是推测,而是从实际运行数据中观察到的。基于这个观察,团队加入了压缩熔断器,每天节省 250K 次 API 调用。
“先观察再修复"不是一条软性的建议,它是驾驭工程的方法论基石。因为在一个提示词驱动的系统中,行为的改变不是通过代码审查可以发现的——你需要在运行时看到"模型开始做出不同的决策”,才能意识到提示词变更的效果。传统的日志和监控不够用了,你需要的是行为级别的可观测性:模型在什么条件下选择了什么工具?压缩后的上下文丢失了哪些关键信息?缓存在哪个注入点中断了?
谁先建立起 AI Agent 系统的行为可观测性基础设施,谁就先拥有了驾驭的资格。
结语
回到开头那个问题:当控制 AI 行为的主要手段从代码变成了提示词,软件工程需要一场怎样的范式革命?
我的判断是:不是革命,而是分化。
传统的软件工程不会消失——Agent 系统的运行时层、工具层、权限层仍然需要严格的代码工程。但一个新的工程维度正在浮现:提示词层面的行为控制、缓存层面的成本管理、压缩层面的信息保留、Flag 层面的策略演进。这些问题的处理方式与传统软件工程截然不同,因为它们的控制对象不是一个确定性的程序,而是一个概率性的模型。
驾驭工程不是要取代软件工程,而是在软件工程旁边长出了一个新的分支——一个专门处理"如何在确定性系统中驾驭不确定性执行者"的工程学科。
Claude Code 不是这个学科的终点,它只是目前最完整的标本。从这个标本中,我们看到的不是某个产品的技术细节,而是一种新的工程思维方式的雏形:尊重模型的概率性本质,用约束而非指令来引导行为,在灵活性成本和缓存稳定性之间精打细算,在观察中理解问题,在测试中验证方案。
这,才是"驾驭"二字的真正含义。
参考:《驾驭工程:从 Claude Code 源码到 AI 编码最佳实践》,基于 Claude Code v2.1.88 公开发布包与 source map 还原分析,GitHub 仓库
如果这篇文章对你有帮助,欢迎赞赏支持我的创作

Guangming Blog
如果这篇文章对你有帮助,欢迎赞赏支持我的创作

支付宝扫码赞赏